Advanced Python Web Scraping: Best Practices & Workarounds

Scraping is a simple concept in its essence, but it’s also tricky at the same time. It’s like a cat and mouse game between the website owner and the developer operating in a legal gray area. This article sheds light on some of the obstructions a programmer may face while web scraping, and different ways to get around them.
Please keep in mind the importance of scraping with respect.
What is Web Scraping?
Web scraping, in simple terms, is the act of extracting data from websites. It can either be a manual process or an automated one. However, extracting data manually from web pages can be a tedious and redundant process, which justifies an entire ecosystem of multiple tools and libraries built for automating the data-extraction process. In automated web scraping, instead of letting the browser render pages for us, we use self-written scripts to parse the raw response from the server. From now onwards in the post, we will simply use the term “web scraping” to imply “Automated web scraping.”
How is Web Scraping Done?
Before we move to the things that can make scraping tricky, let’s break down the process of web scraping into broad steps:
- Visual inspection: Figure out what to extract
- Make an HTTP request to the webpage
- Parse the HTTP response
- Persist/Utilize the relevant data
The first step involves using built-in browser tools (like Chrome DevTools and Firefox Developer Tools) to locate the information we need on the webpage and identifying structures/patterns to extract it programmatically.
The following steps involve methodically making requests to the webpage and implementing the logic for extracting the information, using the patterns we identified. Finally, we use the information for whatever purpose we intended to.
For example, let’s say we want to extract the number of subscribers of PewDiePie and compare it with T-series. A simple Google search leads me to Socialblade’s Real-time Youtube Subscriber Count Page.
From visual inspection, we find that the subscriber count is inside a <p> tag with ID rawCount.

Let’s write a simple Python function to get this value. We’ll use BeautifulSoup for parsing the HTML.
import requests from bs4 import BeautifulSoup html = requests.get(url).content soup = BeautifulSoup(html) return soup.select('#rawCount')[0].textLet’s see the counts now:
get_subscribers('https://socialblade.com/youtube/user/pewdiepie/realtime') '80520035' get_subscribers('https://socialblade.com/youtube/user/tseries/realtime') '79965479'Seems like an easy process, right? What could go wrong?
The answer to this mostly depends upon the way the site is programmed and the intent of the website owner. They can deliberately introduce complexities to make the scraping process tricky. Some complexities are easy to get around with, and some aren’t.
Let’s list down these complexities one by one, and see the solutions for them in the next section.
Complexities of Web Scraping
Asynchronous loading and client-side rendering
What you see is not what you get.
This is one of the most common problems that developers face when scraping a Javascript-heavy website. The initial response that we receive from the server might not contain the information that we expected as per visual inspection.
This happens because the information that we are actually looking for is either rendered at the browser side by libraries like Handlebars or React, or fetched by making future AJAX calls to the server and then rendered by the browser.
A couple of examples of this include:
- Webpages with infinite scrolling (Twitter, Facebook, etc.)
- Webpages with pre-loaders like percentage bars or loading spinners

Authentication
Many websites have some sort of authentication that we’ll have to take care of in our scraping program. For simpler websites, authentication might be as easy as making a POST request with username and password or storing the cookie. However, there can also be certain subtleties like:
- Hidden values: Along with username and password, you might need to add other fields to the POST payload (usually CSRF_TOKEN, but can also be some weird data).
- Setting headers: There might be certain headers that we need to set (referer, authorization, etc.)
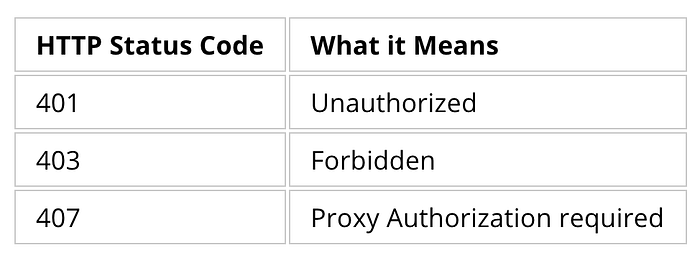
If we get the following response codes back from the server, then it’s probably an indication that we need to get the authentication right to be able to scrape.
Server-side blacklisting
As we mentioned earlier, the answer to “What could go wrong while scraping?” also depends on the intent of the website owners.
There may be anti-scraping mechanisms set up on the server side to analyze incoming traffic and browsing patterns, and block automated programs from browsing their site.
Simple ideas for such analysis include:
Analyzing the rate of requests
If the server is receiving too many requests within a timeframe from a client, it’s a red flag that there is human browsing at the other end. Even worse is getting parallel requests from a single IP.
Another red flag is repetition (client making X requests every Y seconds). Servers can measure such metrics and define thresholds exceeding which they can blacklist the client. The mechanisms can be far more intricate than this, but you get the idea. The banning of a client is usually temporary (in favor of free and open internet for everyone), but in some cases, it can even be permanent.
Inspecting the request headers is also a technique used by some websites to detect non-human users. The idea is to compare the incoming header fields with those that are expected to be sent by real users.
For example, certain tools and libraries send a very distinct user agent while making requests to a server, so servers might choose to selectively allow just a few user agents and filter the rest. Also, some websites may serve different content to different user agents, breaking your scraping logic.
Honeypots
The site’s owners can set up traps in the form of links in the HTML not visible to the user on the browser — the easiest way to do this is to set the CSS as display: none - and if the web scraper ever makes a request to these links the server can come to know that it's an automated program and not a human browsing the site, it'll block the scraper eventually.
Pattern detection
This involves very defined patterns in the way the website is being browsed (time within clicks, the location of clicks, etc.). These patterns might be detected by anti-crawling mechanisms on the server end, leading to blacklisting.
Response status codes that may signal server side blacklisting include:

Redirects and Captchas
Some sites simply redirect their older link mappings to newer ones (like redirecting HTTP links to https ones) returning a 3xx response code.
Additionally, to filter suspicious clients, servers may redirect the requests to pages containing quirky captchas, which our web scraper needs to solve to prove that “it’s a human”.
Companies like Cloudflare, which provide anti-bot or DDoS protection services, make it even harder for bots to make it to the actual content.
Structural complexities
Sometimes it is tricky to crawl through all the webpages and collect the information. For example, pagination can be tricky to get around if every page in pagination does not have a unique URL, or if it exists, but there’s no pattern that can be observed to compute those URLs.
Unstructured HTML
This is when the server is sending the HTML but is not consistently providing a pattern. For example, the CSS classes and attributes are dynamically generated on the server end and are unique everytime. Sometimes, unstructured HTML is also a consequence of bad programming.
iframe tags
Sometimes the content we see on the website is an iframe tag rendered from another external source.
Alright! We’ve listed down the complexities; now it’s time to address the workarounds to them.
Resolving the Complexities of Web Scraping with Python
Picking the right tools, libraries, and frameworks
First and foremost, I can’t stress enough the utility of browser tools for visual inspection. Effectively planning our web scraping approach upfront can probably save us hours of head scratching in advance. Most of the time, the pre-existing (native) browser tools are the only tools that we’ll need for locating the content, identifying patterns in the content, identifying the complexities, and planning the approach.
For web scraping in Python, there are many tools available. We’ll go through a few popular (and self-tested) options and when to use which. For scraping simple websites quickly, I’ve found the combination of Python Requests (to handle sessions and make HTTP requests) and Beautiful Soup (for parsing the response and navigating through it to extract info) to be perfect pair.
For bigger scraping projects (where I have to collect and process a lot of data and deal with non-JS related complexities), Scrapy has been quite useful.
Scrapy is a framework (not a library) which abstracts a lot of intricacies for scraping efficiently (concurrent requests, memory utilization, etc.), and also allows to plug in a bunch of middleware (for cookies, redirects, sessions, caching, etc.) to deal with different complexities. Scrapy also provides a shell that can help in quickly prototyping and validating your scraping approach (selectors, responses, etc.). This framework is quite mature, extensible, and has good community support too.
For JavaScript-heavy sites (or sites that seem too complex), Selenium is usually the way to go. Although scraping with Selenium isn’t as efficient as compared to Scrapy or Beautiful Soup, it almost always gets you the desired data (which is the only thing that matters most of the times).
Handling authentication
For authentication, since we’ll have to maintain cookies and persist our login, it’s better to create a session which will take care of all this. For hidden fields, we can manually try logging in and inspect the payload being sent to the server using the network tools provided by the browser to identify the hidden information being sent (if any).
We can also inspect what headers are being sent to the server using browser tools so that we can replicate that behavior in the code as well, such as if authentication depends on headers like Authorization and Authentication). If the site uses a simple cookie-based authentication (which is highly unlikely these days), we can also copy the cookie contents and add it to your scraper's code (again, we can use built-in browser tools for this).
Handling Asynchronous loading
Detecting Asynchronus loading
We can detect asynchronous loading in the visual inspection step itself by viewing the source of the page (the “View Source” option in the browser on right click) and then searching for the content we’re looking for. If you don’t find the text in the source, but you’re still able to see it in the browser, then it’s probably being rendered with JavaScript. Further inspection can be done with the browser’s network tool to inspect if there are any XHR request being made by the site.
Getting around asynchronous loading
Using a web driver
A web driver is like a simulation of a browser with an interface to be controlled through scripts. It is capable of doing the browser stuff like rendering JavaScript, managing cookies and sessions, and so on. Selenium Web Driver is a web automation framework designed to test UI/UX of websites, but it has also become a popular option to scrape dynamically rendered sites over time.
Needless to say, since web drivers are a simulation of browsers, they’re resource intensive and comparatively slower when compared to libraries like beautifulsoup and scrapy.
Selenium supports multiple languages for scripting, including Python. Usually, it launches a browser instance, and we can see things like clicking and entering data on the screen, which is useful while testing. But if we care about just scraping, we can use “headless browsers” that don’t have UI and are faster in terms of performance.
Chrome Headless is a popular choice for a headless web driver, and other options include Headless Firefox, PhantomJS, spynner, and HtmlUnit. Some of these might require you to install xvfb, and its Python wrapper ( xvfbwrapper or pyvirtualdisplay) to simulate a screen display in virtual memory without producing any actual output on the screen.
Inspecting AJAX calls
This method works on the idea of “ If it’s being displayed on the browser, it has to come from somewhere.” We can use browser developer tools to inspect AJAX calls and try to figure out requests are responsible for fetching the data we’re looking for. We might need to set X-Requested-With header to mimic AJAX requests in your script.
Tackle infinite scrolling
We can tackle infinite scrolling by injecting some javascript logic in selenium (see this SO thread). Also, usually the infinite scroll comprises of further AJAX calls to the server which we can inspect using browser tools and replicate in our scraping program.
Finding the right selectors
Once we locate the element that we want to extract visually, the next step for us is to find a selector pattern for all such elements that we can use to extract them from the HTML. We can filter the elements based on their CSS classes and attributes using CSS selectors. You can refer to this quick cheatsheet for different possible ways of selecting elements based on CSS.
CSS selectors are a common choice for scraping. However, another technique for selecting elements called XPath (a query language for selecting nodes in XML documents) can be useful in certain scenarios. It provides more versatile capabilities, for example:
- Selecting elements based on their content. This is not a recommended practice, but it’s handy for poorly structured pages.
- Search in any direction. We can construct queries that search for grandparents, and then search their child with certain attributes/text. This is not possible with CSS selectors.
Some people argue that XPath is slower than CSS selectors, but in my personal experience, both work equally well. Though sometimes one is faster than the other, the difference is in milliseconds. Also, when scraping not-so-complex and well-structured web pages, I simply use Chrome/Firefox’s selection tool to get the XPath of the target element, plug it into my script, and I’m good to go within seconds. Having said that, there are few checks that might come in handy while coming up with the selectors:
By pressing Ctrl + F in the DOM inspector, we can use CSS expression (or XPath) as a search query. The browser will cycle through and let us see all of the matches. It's a quick way to check that the expression works.
- Selecting the elements by IDs is faster, so we should prefer IDs wherever it’s available.
- XPpaths are more tightly coupled to the HTML structure than CSS selectors, i.e., XPath is more likely to break if there’s some change in the way HTML is structured on a page.
Tackling server-side blacklisting
In the last section, we discussed some of the techniques servers use to detect automated bots and throttle them. There are a few things that we can do to prevent our scraper from getting detected:
- Using proxy servers and IP rotation. To the server, it’ll look like there are multiple users browsing the site. There are multiple sites where you can find a list of free proxies to use (like this). Both
requestsandscrapyhave functionalities to use rotating proxies. A couple of things to keep in mind while using proxies are:
- Free proxy addresses are usually temporary; they’ll start giving connection errors after some time. So it’s better to provide the proxies dynamically. We can either scrape the list of active proxies (yeah, scraping for scraping further) from the proxy listing sites or use some sort of API (a few premium Proxy services have this functionality).
- Some proxies set and send the
HTTP_X_FORWARDED_FORorHTTP_VIA(or both) header which server can use to detect that we're using a proxy (and even the real IP address). So it's advisable to use elite proxies (proxies which send both these header fields as blank).
2. User-agent spoofing and rotation. The idea is to pass a different user-agent (or multiple different user-agents in rotation) header field to fool the server. A list of different possible User-agents is available here. Spoofing user-agent may not always work because websites can come up with client-side JS methods to identify if the agent is what it is claiming. We should also keep in mind that rotating User agents without rotating IP address in tandem may signal a red flag to the server.
3. Reducing the crawling rate by adding random time waits between actions (like making requests, entering data, clicking elements, etc.). This will randomize the browsing pattern and make it harder for the server to differentiate between our scrape and a real-world user.
Scrapy has an auto-throttle extension to get around with throttling. It has a bunch of configurable settings to simulate real-world browsing patterns.
Handling redirects and captchas
Modern libraries like requests already take care of HTTP redirects by following through them (maintaining a history) and returning the final page. Scrapy also has a redirect middleware to handle redirects. Redirects aren't much of a trouble as long as we are ultimately redirected to the page we seek. But if we're redirected to a captcha, then it gets tricky.
Very simple text-based captchas can be solved using OCR (there’s a python library called pytesseract for this). Text-based captchas are slippery slopes to implement these days with the advent of advanced OCR techniques (that are based on Deep Learning, like this one), so it’s getting harder to create images that can beat machines but not humans.
Also in case we don’t want to bear the overhead of solving captchas, there are multiple services available which provide APIs for the same, including Death by Captcha, Antigate, and Anti Captcha. Some of these services employ real humans who are paid to solve the captcha for you. Nevertheless, you might be able to avoid captchas to some extent by using proxies and IP rotation.
Handling iframe tags and unstructured responses
For iframe tags, it's just a matter of requesting the right URL to get the data back that you want. We have to request the outer page, then find the iframe, and then make another HTTP request to the iframe's src attribute. Also, there's nothing much that we can do about unstructured HTML or URL-patterns besides having to come up with hacks (coming up with complex XPath queries, using regexes, etc.).
Other Useful scraping tools and libraries
Following tools might come in handy for you for some specific cases.
- Newspaper: Newspaper3k is a library for scraping Articles. It supports multiple languages, provides API to get meta info like author details and publication date, and NLP features like extracting summaries and keywords, extracting authors.
- PyAutoGUI: PyAutoGUI is a GUI automation module that lets you control keyboard and mouse programmatically. A nice feature PyAutoGUI provides is locating an image on the screen. I’ve observed a few people using PyAutoGUI to navigate through the site.
- EditThisCookie browser extension is pretty useful when you’ve to play around with cookies and their contents.
- cloudflare-scrape: I’ve used this module in the past to get around Cloudflare’s anti-bot checks. A nice thing about the scraping ecosystem in Python is there are a lot of functionalities that you’ll find open-sourced or in the form of snippets on Stack Overflow.
- tcpdump: You can use tcpdump to compare header of two requests (the one that your scraper is sending, and the other that your browser is sending while actually surfing the site)
- Burp Suite: Burp Suite is useful for intercepting the requests browser makes on the site and analyzing them.
- Stem: Just in case you want to make requests using python over TOR.
- Visual scraping services like Octoparse, Portia (open-source and built by the scrapy team), ParseHub, Dext, and FMiner.
- Browser extensions like Web Scraper, Data Scraper, and Agenty (for Chrome).
Scraping with Respect
In this post, we covered typical complexities involved in scraping websites, their possible workarounds, and the tools and libraries that we can use with Python in mind.
As mentioned in the beginning, scraping is like a cat-and-mouse game operating in a legal gray area, and can cause trouble to both the sides if not done respectfully. Violation of copyrights and abuse of information may invite legal consequences. A couple of instances that sparked controversies are the OK Cupid data release by researchers and HIQ labs using Linkedin data for HR products.
Robots exclusion standard was designed to convey the intent of the site owners towards being indexed/crawled. Ideally, our web scraper should obey the instructions in the robots.txt file. Even if the robots.txt allows scraping, doing it aggresively can overwhelm the server, causing performance issues or resource crunch on the server-end (even failures).
It’s good to include a back-off time if the server is starting to take longer to respond. Also, a less popular opinion is contacting the site-owners directly for APIs and data-dumps before scraping so that both sides are happy.
Did we miss any web scraping tips for Python developers? If so, let us know in the comments section below!
Learn Python by building projects with DevProjects
Originally published at https://www.codementor.io.
